https://platform.openai.com/docs/api-reference/audio
OpenAI API
OpenAI에서 개발한 새로운 AI 모델에 액세스하기 위한 API
platform.openai.com
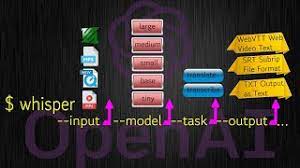
오디오를 텍스트로 변환하는 방법을 알아보세요. 음성을 텍스트로 변환하는 방법을 알아보세요.
관련 가이드: 음성을 텍스트로
OpenAI API
OpenAI에서 개발한 새로운 AI 모델에 액세스하기 위한 API
platform.openai.com
이것은 한국어로 이 사이트를 설명하는 내 블로그 게시물입니다.
https://coronasdk.1287
가이드 – 음성을 텍스트로
https://platform.openai.com/docs/guides/speech-to-text OpenAI API OpenAI에서 개발한 새로운 AI 모델에 액세스하기 위한 API platform.openai.com Speech to Text 텍스트 변환에 오디오를 추가하는 방법 알아보기 로 변경하려면 .
coronasdk.tistory.com
전사 작성
우편 https://api.openai.com/v1/audio/transcriptions
오디오를 입력 언어로 변환합니다.
입력한 언어로 음성 메시지를 전사(전사)합니다.
import os
import openai
openai.api_key = os.getenv("OPENAI_API_KEY")
audio_file = open("audio.mp3", "rb")
transcript = openai.Audio.transcribe("whisper-1", audio_file){
"file": "audio.mp3",
"model": "whisper-1"
}{
"text": "Imagine the wildest idea that you've ever had, and you're curious about how it might scale to something that's a 100, a 1,000 times bigger. This is a place where you can get to do that."
}
요청 본문
mp3, mp4, mpeg, mpga, m4a, wav 또는 webm 형식 중 하나로 변환할 오디오 파일입니다.
텍스트로 변환할 오디오 파일입니다. mp3, mp4, mpeg, mpga, m4a, wav 또는 webm 형식 중 하나여야 합니다.
사용할 모델의 ID입니다. 오직 속삭임-1 현재 사용 가능합니다.
사용할 모델의 ID입니다. 현재 Whisper 1 모델만 사용할 수 있습니다.
모델의 스타일을 안내하거나 이전 오디오 세그먼트를 계속하는 선택적 텍스트입니다. 그만큼 즉각적인 오디오 언어와 일치해야 합니다.
모델의 스타일을 안내하거나 이전 오디오 세그먼트를 계속하는 선택적 텍스트입니다. 알림은 오디오 언어와 일치해야 합니다.
json, text, srt, verbose_json 또는 vtt 옵션 중 하나의 성적표 출력 형식입니다.
기록된 값의 출력 형식입니다. json, text, srt, verbose_json 또는 vtt 형식 중 하나입니다.
샘플링 온도는 0과 1 사이입니다. 0.8과 같은 높은 값은 출력을 더 무작위로 만들고 0.2와 같은 낮은 값은 더 집중적이고 결정적입니다. 0으로 설정하면 모델은 다음을 사용합니다. 로그 확률 특정 임계값에 도달할 때까지 온도를 자동으로 높입니다.
샘플링 온도 범위는 0에서 1까지입니다. 0.8과 같이 값이 높을수록 출력이 더 무작위로 생성되고 0.2와 같이 값이 낮을수록 더 집중되고 결정적입니다. 값이 0이면 모델은 특정 임계값에 도달할 때까지 자동으로 로그 우도를 사용합니다. 온도 올려.
입력 오디오의 언어입니다. 에서 입력 언어 제공 ISO-639-1 형식은 정확도와 대기 시간을 향상시킵니다.
입력 오디오의 언어입니다. ISO-639-1 형식으로 입력 언어를 제공하면 정확도와 대기 시간이 향상됩니다.
번역 만들기
우편 https://api.openai.com/v1/audio/translations
오디오를 영어로 번역합니다.
음성 데이터를 영어로 번역합니다.
import os
import openai
openai.api_key = os.getenv("OPENAI_API_KEY")
audio_file = open("german.m4a", "rb")
transcript = openai.Audio.translate("whisper-1", audio_file){
"file": "german.m4a",
"model": "whisper-1"
}{
"text": "Hello, my name is Wolfgang and I come from Germany. Where are you heading today?"
}
요청 본문
다음 형식 중 하나로 변환할 오디오 파일: mp3, mp4, mpeg, mpga, m4a, wav 또는 webm.
텍스트로 변환할 오디오 파일입니다. mp3, mp4, mpeg, mpga, m4a, wav 또는 webm 형식 중 하나여야 합니다.
사용할 모델의 ID입니다. 오직 속삭임-1 현재 사용 가능합니다.
사용할 모델의 ID입니다. 현재 Whisper 1 모델만 사용할 수 있습니다.
모델의 스타일을 안내하거나 이전 오디오 세그먼트를 계속하는 선택적 텍스트입니다. 그만큼 즉각적인 영어로 되어 있어야 합니다.
모델의 스타일을 안내하거나 이전 오디오 세그먼트를 계속하는 선택적 텍스트입니다. 알림은 오디오 언어와 일치해야 합니다.
json, text, srt, verbose_json 또는 vtt 옵션 중 하나의 성적표 출력 형식입니다.
성적표 출력의 형식입니다. json, text, srt, verbose_json 또는 vtt 형식 중 하나입니다.
샘플링 온도는 0과 1 사이입니다. 0.8과 같은 높은 값은 출력을 더 무작위로 만들고 0.2와 같은 낮은 값은 더 집중적이고 결정적입니다. 0으로 설정하면 모델은 다음을 사용합니다. 로그 확률 특정 임계값에 도달할 때까지 온도를 자동으로 높입니다.
샘플링 온도 범위는 0에서 1까지입니다. 0.8과 같이 값이 높을수록 출력이 더 무작위로 생성되고 0.2와 같이 값이 낮을수록 더 집중되고 결정적입니다. 값이 0이면 모델은 특정 임계값에 도달할 때까지 자동으로 로그 우도를 사용합니다. 온도 올려.